
My Linux Job Scheduler
History
The job scheduler I wrote as cron didn't provide me with what I needed, such as job completion dependancy support, file arrival watchers, remote management etc. As well as all that it provides functional user roles for granular security. Ok I wrote it for myself and my needs, but I have been using this for over twenty years now (first used on Fedora Core 3) and the needed 'tweaks' for improvement stopped quite a few years ago, so it's probably usefull to others.
A list of the key features it provides is further down this page. While this page also covers the web interfaces it is probably worth pointing out you would really only install those onto one or two servers and use those to manage all the others, and mention that you may not need them at all as the command line interface running on a server is able to connect to a scheduler on any of the other servers also (firewall rules permitting) if you want to script your own management tools.
I do still make changes or 'tweaks' as needed (such as a real bug fixed in Nov 2022) so if you use this you should check back occasionally.
Requirements
A key design decision made with this was that it must be standalone, no dependencies on any SQL database
servers, so it uses flat files as it's databases; so if you get upward of 100 jobs it may take a performance hit,
but it's batch so who cares. That decision allows it to be deployed to low performance servers
without the need for database software to be deployed as well.
As such there are no database dependencies.
There are compiler dependencies, this must be complied using either GCC V3.4.2 or below, or preferably GCC V4.5.1 and any higher version. While it will compile cleanly with the versions in the middle it will just segfault so if compiling from source use a supported GCC version. If you have issues compiling on Linux the binary (rpm+deb packaged here) versions are staticly linked so will run.
It will not compile (at present, on openindiana hipster with package gcc-14), so compatability there is a work in progress as (many standard .h include files have different structs). I have only started revisiting this as true solaris 8 was the last solaris system it compiled on before I had no more solaris machines :-).
The latest compile runs I have tested are
Works OK: gcc (GCC) 10.3.1 20210422 (Red Hat 10.3.1-1) Works OK: gcc (Debian 12.2.0-14+deb12u1) 12.2.0 Compile Failure: gcc (OpenIndiana 14.3.0-oi-1) 14.3.0
Download and Documentation
While in order to get any up-to-date fixes/changes you should download and compile the latest source code from github; there are also install packages (that will not always be the latest version) for RHEL (all packages) and Debian (just the scheduler) sytems available from here.
The application source and latest documentation is now hosted on github and not available for download directly from here. To see the application files individually the URL is https://github.com/MarkDickinson/scheduler. To install from github, ensure you have git installed and
cd yourdir
mkdir scheduler
cd scheduler
git init
git clone https://github.com/MarkDickinson/scheduler.git
After the repository has downloaded just follow the installation instructions. The git pull will also retrieve all the manuals (in opendocument format) plus the man pages.
If you are not interested in the very small manual labour of installing from source, there are some older prebuilt RPM (all) and DEB (scheduler only) packages although be aware you may (ok will) probably have some issues in using these now.
Unsupported Documentation
The latest documentation is always at githup. As that is in opendocument format I keep some copies of those documents in PDF format here; but they are not guaranteed to be up to date as I only refresh these PDF copies after major changes.
- jobsched_cmd user guide
- Job Scheduler Server Configuration Manual which is the installation/admin guide
- Job Scheduler Security Guide which has recomeded security settings
- the 100+ page Job Scheduler Messages Manual
- And also the miscellaneous utilites manual
- Old (really out of date, about 2004) versions of the scheduler manuals are online (they need javascript enabled). Only retained because I spent so much effort creating them, before I them decided PDF was the way go go and created the opendocument format files now on github
- Known bugs: Known bugs are now recorded in the KNOWN_ISSUES document in the github repository.
Key functionality provided
The key features of this application are...
- Allows job dependencies to be established
- Allows up to five dependencies per job which can be a mix of both prior jobs completing sucessfully or files arriving; with files the dependency is not satisfied until the file last modification time is at least 5 minutes old in order to stop triggering a job while the file is still being written to by a file transfer
- Permits manual overrides of dependencies at a job or daily global level
- Workload throttling.
- Unlike cron which if it has 20 jobs to start at the same minute it will start them and impact your system; the scheduler will run a maximum of five (5) simultaneous jobs and just queue the others to start as each of the running ones stop so no more than five run at a time. Currently five is what is hard coded in the source code, I may one day make that dynamically reconfigurable to cater for changing workloads but uf you need to change it currently change it in the source code and recompile
- Runs batches as logical days.
- Will not schedule on a new days jobs until the current days has completed
- Will raise an alert if the newday scheduling is forced to run late
- When newday scheduling is late scheduling can be configured to go into an alert state, or into a retry wait state
- Note: for jobs that "repeatevery" such as run every 15 minutes rather than once a day they will not be scheduled on for a time after the 'newday' time so if jobs are running late or a job is in alert state preventing the newday from running the repeat jobs will also not run; they will be scheduled on again as soon as the condition preventing the newday from running is cleared [but if jobs must run an at exact time still use cron as the scheduler is quite likely to queue jobs]
- Calendar file support.
- Jobs can be scheduled based on a JOB calendar
- Jobs can be prevented from being scheduled on based on a HOLIDAY calendar
- should a job using a calendar have the calendar expire (no remaining dates left) a "job listall" command will show a calendar expired message rather than the next scheduled date
- Alert handling of failed jobs
- failed jobs are placed into an alert state for review, a job in this state can be restarted or forced into an OK state
- alerts for failed jobs or scheduler error conditions can be forwarded to external scripts to allow integration with any existing tools you may use for alert monitoring or automation
- note: if a job is in alert state it is considered as not to have run so will prevent newday processing until corrected
- Discrete job log files and redirection of output, and input
- Every job running will log (redirect) anything written to stdout or sdterr to a job log file that is the name of the job (output is not mixed with any other jobs output); allowing you jobs to be as verbose as they want (unlike cron that would generate an email if there is output produced resulting in user trying to code jobs in ways that try to prevent output jobs run under my scheduler should be as verbose as needed for activity logging or debugging). These logs are appended to so no data is lost with job reruns; as they are appended to they will grow in size so you should have a job to archive/rotate them weekly (or daily as you see fit) in which case refer to the NULL job type mentioned further down this list
- Redirection of input is also done, from /dev/null, so should for any reason your batch job be so badly coded it prompts for interactive input it will get a response, maybe not the response it wants but a response. This was added when I reran a backup job to do a tar and the tar prompted for file exists do I want to overwrite and it took me ages to figure out why the job had hung. So now programs that prompt get a response and if they don't like it (assuming you check $? for response codes in your scripts) your job should go into alert state so you can fix whatever is causing the prompt, the offending prompt will be in the job log so you can find it easily
- Internal user security allows clear role seperation
- Guest/browse (default), can only do read queries
- Job and Calendar authority users, can update databases but not schedule or manage active jobs
- Operator authority users, can schedule on jobs and manage active jobs, can't touch database definitions
- Security group users, can only manage user records; cannot alter anything else
- Administrators, can do everything
- Multiple user interfaces
- Command line interface. This is the administrators tool. It provides all the functions required to manage and support all the job and calandar definitions, customise the server options etc. Can do absolutely everything
- JSP web browser interface, tested under Tomcat and Jetty. Allows full monitoring and control of all configured local and remote job schedulers. Also allows the ability to globally manage users, job definitions, calendars etc across all local and remote servers from a single screen. Forces user to login under their personal userids so allows activity tracking
- CGI based web browser interface to provide an operations view. Provides an interface for job monitoring and control of the current days scheduled jobs. As it's CGI based and issues commands under the apache (or whatever your web server is is) userid so no access to update databases is provided with this. Note: this has been obsoleted by the JSP interface, but is still provided as a functional sample for sites without Tomcat or similar. It is not supported anymore by the author (as it required that the web server userid be given operator access which is a security risk, the JSP interface on the other hand requires individual user logins).
- Completely standalone therefore fully portable
- A deliberate decision was made to make this totally standalone, with no database dependencies (ie: you do not need a database server such as MySQL/DB2/Cloudscape etc.), it manages it's own databases as flat files. As such it is probably not suitable for sites that want to run thousands of jobs as things would start to really slow; however batch is batch and is expected to be slow so it may not bother you (however if you have thag many jobs you would not be using cron but have a commercial product instead). The decision to use flat files instead of database software was made as I want this to be fully portable across all platforms, this way it is
- As such, it comes with it's own database offload and reload tool; so yes you can backup (should be done daily) and restore your schedules.
- Unique NULL job type for maintenance
-
As always added for my specific needs, any job name beginning with NULL will execute
with the following characteristics
- It runs exclusively, no other job on the scheduler is permitted to run while a jobname prefixed NULL- runs
- NULL- jobs do not write to a job log file, its output is discarded
-
As always added for my specific needs, any job name beginning with NULL will execute
with the following characteristics
User Interfaces
JSP (Java Server Pages) Interface
The JSP interface is intended for site wide administration rather than for day today operations use. Using the JSP interface from a single login screen you are connected to all the remote job schedulers you are authorised to use and you are able to perform global operations such as defining a new job or calendar entry to multiple (or selected) remote servers in one request.
It provides full administration functions to all the remote servers, anything that can be done locally in the command line interface can be done globally from the JSP interface. As users login to the JSP interface using their job scheduler userid/password combination the security roles are still enforced; ie: operations can play with job scheduled but not create new jobs, security user can play with userids but nothing else, admins are still god.
As a full administration interface it can also provide all the services available via the CGI interface, if the user is authorised to access those functions.
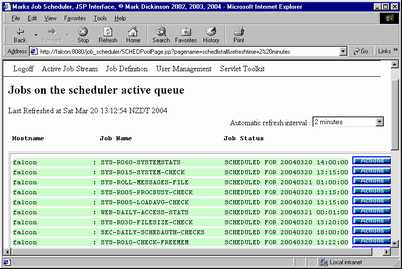
This has only been tested under Apache jakarta Tomcat and Jetty.
The CGI Interface
The CGI based PERL interface is primarily for site wide operational monitoring, it can be used to
monitor and control the current days active job stream
across all servers running the job scheduler application,
the active job stream being defined as the jobs submitted into the schedulers for the
current day and the job alert queues for any failed jobs.
It is designed primarily as an operations tool, jobs can be monitored, held, released and requeued,
failed jobs may be restarted from the alert queue, and job dependencies can be overridden.
It cannot be used for any database administration functions (user/job/calendar maintenance etc), that limitation is because as a CGI interface it runs under the http process sudo job scheduler userid rather than a real persons userid so database update functions cannot be permitted as it would break the audit trail. Database viewing functionality is provided for job stream related functions, but no updates allowed. (actually you could add database functions, but as shipped the 'apache' userid is authorised only for a operations role, you could increase its authority level but I strongly advise against it).
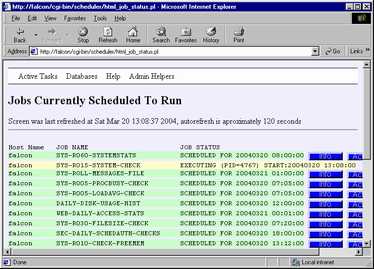
The Command Line interface
The command line interface is where the admins will probably spend all their time, while the JSP interface provides full admin functionality you can't script a web page; you can wrap scripts around the command line interface. Admins may find it a little frustrating at first as while it is the main interface to the scheduler it is also intended to be used for scripts and as such does a fast fail (ie: stops immediately) at the first error found; so if you make a typo on the command line interface interactively you have to start all over again, thats deliberate and it will not be changed :-).
The command line interface is also able to connect to remote servers, so can be used to manage remote servers in a one at a time connection as opposed to the JSP interfaces global update functionality.
This command line interface has a few benifits over all the other interfaces. First it is always going to work correctly as this is the interface (of course, the one that can be scripted) that is used to run tests against the server whenever changes are made to any of the code. Secondly as the admin tool this is the only interface that can manipulate the debugging and tracing levels, the message logging levels, and a few other internals that normal users will never need.
Here are a few output snapshots from the command line interface, starting with the
active job queue display as that was used in the earlier examples. Then
the scheduler status display and a demo on the online help function.
ACTIVE DAYS JOB SCHEDULE
command:sched listall
DAILY-DISK-USAGE-HIST SCHEDULED FOR 20080518 12:00:00
WEB-DAILY-ACCESS-STATS SCHEDULED FOR 20080519 00:01:00
SEC-DAILY-SCHEDAUTH-CHECKS SCHEDULED FOR 20080518 18:00:00
JS_-DAILY-SNAPSHOT SCHEDULED FOR 20080518 17:30:00
WAITING(0):JS_-DAILY-LOG-CLEANUPS
NULL-ARCHIVE-JOBLOGS SCHEDULED FOR 20080518 21:30:00
WAITING(0):JS_-DAILY-LOG-CLEANUPS
SYS-RPM-BACKUP SCHEDULED FOR 20080518 22:00:00
SYS-DAILY-DISK-CLEANUP SCHEDULED FOR 20080518 17:30:00
JS_-DAILY-LOG-CLEANUPS SCHEDULED FOR 20080518 23:00:00
SYS-DAILY-SOURCE-BACKUP SCHEDULED FOR 20080518 22:15:00
SEC-DAILY-LOG-ARCHIVE SCHEDULED FOR 20080518 23:30:00
WEB-DAILY-SEARCH-INDEX SCHEDULED FOR 20080519 03:30:00
SYS-R015-CHECK-CROND SCHEDULED FOR 20080518 09:30:00
WEB-ERROR-REPORT SCHEDULED FOR 20080518 23:55:00
SYS-DAILY-MYSQL-BACKUP SCHEDULED FOR 20080518 17:00:00
SYS-WEEKLY-HOMEDIR-BKP EXECUTING (PID=11366) START:20080518 09:20:00
SCHEDULER-NEWDAY SCHEDULED FOR 20080519 07:00:00
SCHEDULER CURRENT CONFIGURATION AND LOG/DEBUG LEVELS
command:sched status
Job Scheduler Server[v1.19] by Mark Dickinson 2001-2021 (GPLV2 Release)
Server Version : SCHEDULER V1.20 (25Nov2022)
Server Status : ENABLED (running jobs)
Log Level : WARN+
Debug Levels : server 0, utils 0, jobslib 0, apilib 0
alerts 0, calendar 0, schedlib 0, bulletproof 0
user 0, memory 0
show scheduler completed/deleted jobs also is 0
Catchup Flag : OFF
New Day Time : 07:00 Last New Day Runtime : 20260711 07:00:00
Configured Next New Day Runtime : 20260712 07:00:00
New Day Pause Action is to go dependant on a job waiting to run
-- Total USER Jobs on scheduler queue = 13 (0 executing currently)
-- Number of jobs on the alert queue = 0
EXAMPLES OF THE COMMAND INTERFACE ONLINE HELP COMMANDS
command:help
Job Scheduler, Mark Dickinson, 2002
These help screens display the syntax of the commands only
to be used as a guide. Do not use them without refering to
the manual. NEVER use commands marked (***READ THE MANUAL FIRST***)
unless you have read the manual.
You need to specify what subsystem you wish help for.
Defined subsystems are...
JOB, ALERT, CAL, DEP, SCHED, USER, DEBUG, LOGIN, LOGOUT or OPEN.
Syntax: HELP <subsystem>
ie: HELP DEP
command:help alert
Job Scheduler, Mark Dickinson, 2002
These help screens display the syntax of the commands only
to be used as a guide. Do not use them without refering to
the manual. NEVER use commands marked (***READ THE MANUAL FIRST***)
unless you have read the manual.
The alert commands are used to manage jobs that have
been placed onto the alert queue.
ALERT ACK <jobname> ALERT INFO <jobname>
ALERT LISTALL ALERT RESTART <jobnname>
ALERT FORCEOK <jobname> (*** READ THE MANUAL FIRST ***)
command:
command: