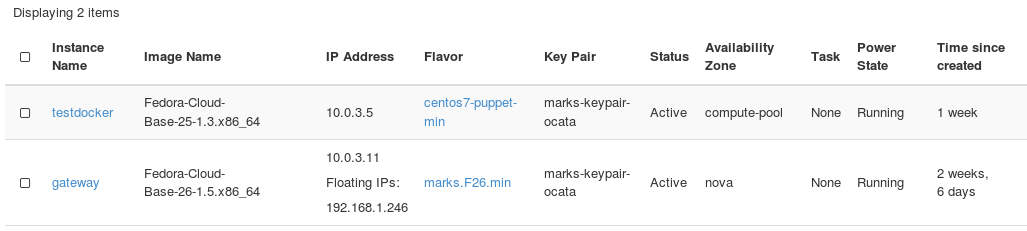
This post was going to be simply about how the only issue I had from upgrading all my core servers to F26 had no issues other than nagios. The title has been updated and the topic slightly changed due to packages suddenly disappearing from totally unrelated CentOS7 repos.
Anyway I upgraded all my F23/F24/F25 systems to F26 to have a nice standard system base again, made possible now the rpmfusion repos have “motion” available for F26 which blocked be from upgrading one of my VM host servers above F23 previously.
I used the dnf-plugin-system-upgrade method on all servers upgraded; although I had to use the –allowerasing option on two of them. The upgrades worked seamlessly and mysql_upgrade was only needed on the F23/F24 ones, the ones that were F25 reported the database was up to date when mysql_upgrade was run.
One issue identified was that after the upgrade apache had reverted back to using privateTmp directories again (reported by my nagios check for that when I finally got most of nagios working again).
Only one issue from the upgrades identified so far, Nagios and nrpe
The only major issue from the upgrades, which is still an issue, is that NRPE and NAGIOS no longer want to talk to each other.
After upgrading a nrpe client server nrpe logs were full of the messages “Error: Could not complete SSL handshake with 192.168.1.170: 1”, and no it was not an allowed_hosts issue, everything was working prior to the upgrade.
So I decided to upgrade all servers to F26 including the nagios server to see if that resolved the problem, and it did not resolve the problem but made the issues worse in that a few of the plugins I use stopped working as well.
Anyway there are lots of search hits on the SSL handshake problem, the root cause seems to be nrpe is built from an old version of openssl and on machines using later versions of openssl it is never going to work. The nagios forums provide the only solution, which is turning SSL off for nrpe. Which is a fair bit of work,
- on every server running the nrpe client you must (1) “vi /usr/lib/systemd/system/nrpe.service” and insert a -n in the command to start the nrpe daemon, (2) “systemctl daemon-reload” to pick up the changes, (3) restart the nrpe service
- on the nagios host(s) “vi /etc/nagios/objects/commands.cfg” and insert a -n into the check_nrpe command (note: if you blindly copied the commands.cfg.rpmnew over commands.cfg you will have to re-add the check_nrpe command as per the nrpe installation documentation (and any other commands you defined))
That had everything chatting to most hosts again with many of the checks running. But there is still the issue that some of the plugins just no longer work.
The ones that just broke are the ping check and current load complaining about missing arguments, and total processes which reports unable to read output. Nothing wrong with the nrpe or nagios configuration, the plugins just do not work. Examples of running them manually as root on machines with selinux permissive and “setenforce 0” (so not a security issue) are below.
[root@nagios objects]# /usr/lib64/nagios/plugins/check_ping
check_ping: Could not parse arguments
Usage:
check_ping -H -w ,% -c ,%
[-p packets] [-t timeout] [-4|-6]
[root@nagios objects]# /usr/lib64/nagios/plugins/check_ping -H 127.0.0.1 -w 100.0,20% -c 500.0,60% -p 5 -t 2 -4
CRITICAL - You need more args!!!
Could not open pipe:
[root@vmhost3 nagios]# /usr/lib64/nagios/plugins/check_load
check_load: Could not parse arguments
Usage:
check_load [-r] -w WLOAD1,WLOAD5,WLOAD15 -c CLOAD1,CLOAD5,CLOAD15
[root@vmhost3 nagios]# /usr/lib64/nagios/plugins/check_load -r -w .15,.10,.05 -c .30,.25,.20
CRITICAL - You need more args!!!
Error opening
[root@vmhost3 nagios]#
[root@vmhost3 nagios]# /usr/lib64/nagios/plugins/check_procs -w 150 -c 200
Unable to read output
[root@vmhost3 nagios]# /usr/lib64/nagios/plugins/check_procs
Unable to read output
As they are supplied plugins they should just work, hopefully those issues get resolved by updates in the next 3-4 weeks, the check_ping appears to be critical, with it not working all hosts are marked down or unreachable… so I replaced that with my own command in the check_host_availability command to work around that in the meantime.
Second unresolved nagios issue
While all the Fedora26 servers are chatting OK the CentOS7 servers no longer accept connections from the F26 nagios/nrpe packages. Below is basic debugging from my nagios server
- can ping a CentOS7 host from the F26 nagios server
- cannot connect to port 5666 on a CentOS7 host from a F26 nagios server
- can ssh to the CentOS7 host from the F26 nagios server, so the “no route” error message is misleading
- can connect to port 5666 on the CentOS7 server from the CentOS7 server
- and as the CentOS7 servers are just for running openstack components
- firewalld is not running on the CentOS7 server, it is not a firewall problem
- selinux is disabled on the CentOS7 servers, it is not a security problem
[mark@nagios ~]$ telnet 192.168.1.172 5666
Trying 192.168.1.172...
telnet: connect to address 192.168.1.172: No route to host
[mark@nagios ~]$ ping -c1 192.168.1.172
PING 192.168.1.172 (192.168.1.172) 56(84) bytes of data.
64 bytes from 192.168.1.172: icmp_seq=1 ttl=64 time=0.466 ms
--- 192.168.1.172 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 0.466/0.466/0.466/0.000 ms
[mark@nagios ~]$ ssh root@192.168.1.172
root@192.168.1.172's password:
Last login: Mon Jul 17 11:55:11 2017 from 192.168.1.170
[root@region1server1 ~]# netstat -an | grep 5666
tcp 0 0 0.0.0.0:5666 0.0.0.0:* LISTEN
tcp6 0 0 :::5666 :::* LISTEN
[root@region1server1 ~]# firewall-cmd --list-ports
FirewallD is not running
[root@region1server1 nagios]# telnet localhost 5666
Trying ::1...
Connected to localhost.
Escape character is '^]'.
Connection closed by foreign host.
[root@region1server1 nagios]# telnet 192.168.1.172 5666
Trying 192.168.1.172...
Connected to 192.168.1.172.
Escape character is '^]'.
Connection closed by foreign host.
Latest update is… on a fresh CentOS7 install for further testing
Yes I know that has nothing to do with a F26 upgrade, but pherhaps it indicates a bigger issue ?.
Found when I was testing a puppet agent run in a CentOS7 agent, nrpe and nagios-plugins-all are no longer in the CentOS7 repo !.
[root@agenttest ~]# yum search nrpe
Loaded plugins: fastestmirror
Loading mirror speeds from cached hostfile
* base: mirror.xnet.co.nz
* extras: mirror.xnet.co.nz
* updates: mirror.xnet.co.nz
Warning: No matches found for: nrpe
No matches found
[root@agenttest ~]# yum search nagios-nrpe
Loaded plugins: fastestmirror
Loading mirror speeds from cached hostfile
* base: mirror.xnet.co.nz
* extras: mirror.xnet.co.nz
* updates: mirror.xnet.co.nz
Warning: No matches found for: nagios-nrpe
No matches found
[root@agenttest ~]# yum provides nrpe
Loaded plugins: fastestmirror
Loading mirror speeds from cached hostfile
* base: mirror.xnet.co.nz
* extras: mirror.xnet.co.nz
* updates: mirror.xnet.co.nz
base/7/x86_64/filelists_db | 6.6 MB 00:00:35
extras/7/x86_64/filelists_db | 1.1 MB 00:00:05
puppetlabs-pc1/x86_64/filelists_db | 1.0 MB 00:00:06
updates/7/x86_64/filelists_db | 4.3 MB 00:00:19
No matches found
[root@puppet nrpe]# yum provides /usr/sbin/nrpe
Loaded plugins: fastestmirror
Loading mirror speeds from cached hostfile
* base: mirror.xnet.co.nz
* extras: mirror.xnet.co.nz
* updates: mirror.xnet.co.nz
No matches found
[root@puppet nrpe]#
The nrpe package (and most of the nagios ones) appear to have been removed from the CentOS7 repositories now !. Rechecked the machines I do have it installed on and it did come come from the CentOS repos.
root@region1server2 nagios]# rpm -qi nrpe
Name : nrpe
Version : 2.15
Release : 4.el7
Architecture: x86_64
Install Date: Mon 17 Jul 2017 10:20:16 NZST
Group : Applications/System
Size : 294857
License : GPLv2
Signature : RSA/SHA1, Thu 23 Feb 2017 09:55:04 NZDT, Key ID f9b9fee7764429e6
Source RPM : nrpe-2.15-4.el7.src.rpm
Build Date : Sat 27 Dec 2014 08:42:09 NZDT
Build Host : c1bg.rdu2.centos.org
Relocations : (not relocatable)
Packager : CBS
Vendor : Centos
URL : http://www.nagios.org
Summary : Host/service/network monitoring agent for Nagios
Description :
Nrpe is a system daemon that will execute various Nagios plugins
locally on behalf of a remote (monitoring) host that uses the
check_nrpe plugin. Various plugins that can be executed by the
daemon are available at:
http://sourceforge.net/projects/nagiosplug
This package provides the core agent.
No big deal you say, well it buggers my next post which was to be how I will be using puppet to keep all my nrpe plugins/commands/custom configs in sync across multiple hosts. Damn, will have to rebuild my testing heat stack to use a F25 test agent instead of a CentOS7 one. Followed by an oops good thing I was writing a post as when I deleted the running stack there went the config I was testing, fortunately its pasted in the next draft post :-).
Unless nagios has suddenly gone 100% commercial I guess the packages will be back in the repos fairly soon; until then I guess I can only automate (whether by heat_patterns, kickstart. or the new toy I am testing puppet) using fedora servers and repos as even if they are now buggy they will eventually be fixed (hopefully).